なぜ静止画に4:2:2は存在しないのか


はじめに
動画のコーデックを扱う際、「4:2:2」や「4:2:0」といった表記を目にすることが多い。これらはクロマサブサンプリング(色差サブサンプリング)のパターンを示す記法である。しかし、静止画フォーマットであるJPEGにおいても同様のサブサンプリングが適用されていることは、意外と知られていない。
本稿では、クロマサブサンプリングの数理的基礎から、各画像フォーマットにおける実装まで、技術的に正確な理解を構築することを目的とする。特に、「なぜ写真の世界では4:2:2がほとんど存在しないのか」という問いに対して、技術的・歴史的観点から考察する。
色空間とサブサンプリングの分離
クロマサブサンプリングを理解するには、まず「なぜ色情報を間引いても画質劣化が少ないのか」という根本的な問いに答える必要がある。この答えは、人間の視覚系の生理学的特性に深く根ざしている。
RGB色空間の特性
RGB色空間は、赤(R)・緑(G)・青(B)の3つの加法混色成分によって色を表現する色空間である。これは、ヒトの網膜に存在する3種類の錐体細胞の分光感度特性に対応している。
- L錐体(長波長錐体)。約560nmにピークを持ち、赤〜黄色の波長域に感度を持つ。RGB色空間のR成分に主に対応。
- M錐体(中波長錐体)。約530nmにピークを持ち、緑〜黄色の波長域に感度を持つ。RGB色空間のG成分に主に対応。
- S錐体(短波長錐体)。約420nmにピークを持ち、青〜紫の波長域に感度を持つ。RGB色空間のB成分に主に対応。
色覚のしくみ

重要なのは、これら3種類の錐体細胞の密度と分布が大きく異なることである。中心窩(視野の中心、最も解像度が高い領域)では、L錐体とM錐体が圧倒的多数を占め、S錐体は極めて少ない。具体的には、S錐体は全錐体の約5-10%程度であり、中心窩ではほぼ存在しない。L錐体とM錐体の比率は個人差が大きく、約1:1から4:1程度の範囲で変動する
参考文献
- Roorda, A., Williams, D. The arrangement of the three cone classes in the living human eye. Nature 397, 520–522 (1999). https://doi.org/10.1038/17383
適応光学を用いて生きている人間の網膜を直接観察し、中心窩における錐体の配置と密度比を測定。中心窩ではS錐体がほぼ存在しないことを確認。
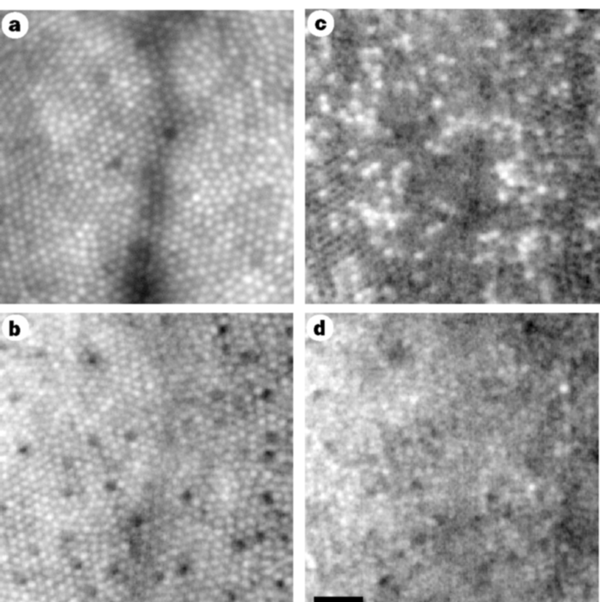
- Curcio CA, Allen KA, Sloan KR, Lerea CL, Hurley JB, Klock IB, Milam AH. Distribution and morphology of human cone photoreceptors stained with anti-blue opsin. J Comp Neurol. 1991 Oct 22;312(4):610-24. doi: 10.1002/cne.903120411. PMID: 1722224.
抗青色オプシン抗体を用いてS錐体を特異的に染色し、人間の網膜全体におけるS錐体の分布を詳細に調査。中心窩ではS錐体が欠如し、周辺部でもL・M錐体に比べて密度が大幅に低いことを実証。

- Sawides, L., de Castro, A., & Burns, S. A. (2017). The organization of the cone photoreceptor mosaic measured in the living human retina. Vision Research, 132, 34-44. https://doi.org/10.1016/j.visres.2016.06.006
複数の被験者の錐体配列を高解像度で分析し、L:M錐体の比率が個人間で1:1から4:1まで大きく異なることを発見。S錐体は常に全体の5-10%程度と非常に少数。

さらに、網膜から視覚皮質へ情報を伝達する神経節細胞は、次の2つの主要な経路に分かれる。
- M細胞経路(大細胞経路)。主にL錐体とM錐体からの信号を統合し、輝度情報(明暗)を高い空間解像度で伝達。時間解像度も高く、動きの検出にも関与。
- P細胞経路(小細胞経路)。L錐体とM錐体、およびS錐体の信号の差分を計算し、色度情報(色相・彩度)を伝達。空間解像度はM細胞経路より低い。
この神経系の構造が、「人間は輝度変化に敏感で、色度変化に鈍感」という特性の生理学的基盤である。M細胞経路は高密度に存在し高い空間周波数まで応答するのに対し、P細胞経路の空間解像度は相対的に低い。
結果として、色差成分(Cb, Cr)をサブサンプリングしても、人間の視覚系がもともと色度の空間的詳細を検出する能力が限られているため、知覚的な劣化は小さく抑えられる。これが、Y'CbCr色空間でクロマサブサンプリングを行う理論的根拠である。
一方、ディスプレイデバイスは物理的にRGB三原色の発光素子を配置しており、RGB色空間での表現は表示デバイスの物理構造と直接対応する。つまり、画像データの保存・伝送段階では人間視覚系に最適化されたY'CbCr色空間を使い、表示段階ではデバイス構造に対応したRGB色空間に変換するという、二段階のアプローチが取られている。
このような人間視覚系の特性を画像の圧縮で活用するために、次に説明するYUV色空間への変換が考案された。
YUV色空間への変換
YUV色空間(より正確にはY'CbCr色空間)は、輝度成分(Y)と2つの色差成分(Cb, Cr)によって色を表現する。この色空間への変換は、人間視覚系(Human Visual System, HVS)の特性に基づいている。
人間視覚系は、明度変化に対しては高い空間周波数まで感度を持つが、色度変化に対しては低周波数域での感度が支配的である。この非対称性が、色差成分を間引いても知覚的劣化が小さいという事実の生理学的根拠となる。
ただし、RGBからY'CbCrへの変換方法は一つではない。使用する色空間規格によって異なる変換係数が定義されており、写真やデジタル画像処理の文脈では、以下の規格が重要な役割を果たしている。それぞれの規格は、ディスプレイ技術の進化と密接に関連している。
ためしにCC0の画像「A Sunday on La Grande Jatte — 1884」で変換を手元で試して遊んでみる。

手元の画像をYUV色空間に変換して遊べるサイト
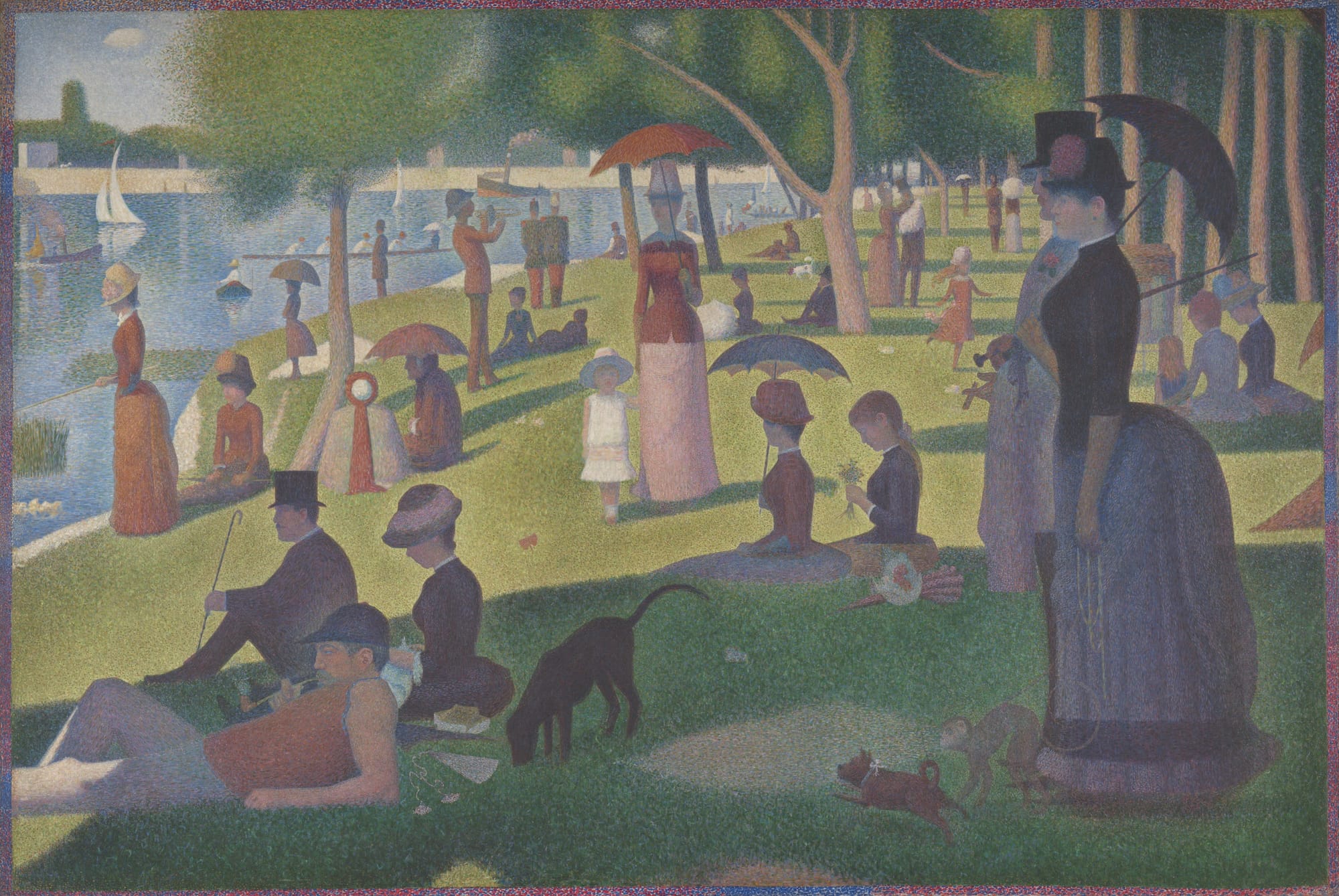


主要な色空間規格の比較 - BT.601、BT.709、BT.2020
RGBからY'CbCrへの変換係数は、使用する色空間規格によって異なる。これらの違いは、ディスプレイ技術の進化と色域拡大の歴史を反映している。
規格間の共通原則
3つの規格(BT.601、BT.709、BT.2020)すべてに共通するのは、人間視覚系の輝度感度特性を反映した設計である。Y'(輝度)成分の計算において、G(緑)成分が最も大きな重み(約59〜72%)を持つ。これは、人間の錐体細胞がG成分の波長域(約530nm)に最も高い感度を持つことに対応している。
次いでR(赤)成分が約21〜30%、B(青)成分が最も小さく約6〜11%の重みを持つ。この順序は、すべての規格で一貫している。
BT.601からBT.709への変更 - ディスプレイ技術の転換
BT.601は1980年代に策定され、CRT(ブラウン管)ディスプレイの蛍光体特性を前提としていた。CRT蛍光体は、特定の発光スペクトルを持ち、特にB(青)成分の発光効率が相対的に高かった。
1990年代後半から液晶・LEDディスプレイへの転換が始まり、BT.709が策定された。液晶・LEDディスプレイは、CRTとは異なる発光特性を持ち、特に以下の変化があった。
- B成分の発光特性の変化:液晶バックライトやLED素子では、青色の発光効率と分光特性がCRT蛍光体と大きく異なる。このため、輝度計算におけるB成分の寄与率が約37%減少した。
- 原色座標の最適化:CRT蛍光体の色度座標から、液晶・LEDディスプレイの実効的な原色座標へと変更された。
BT.709の普及とsRGBとの関係
BT.709は、sRGB色空間と完全に同じ原色座標と白色点(D65)を使用する。sRGBは1996年にHP・Microsoftが策定したウェブ・一般ディスプレイ向けの標準色空間であり、以下の経緯で普及した。
- Windows 95/98、Internet Explorer、Adobe Photoshop 5.0(1998年)がsRGBをデフォルト色空間として採用
- JPEG規格のExif 2.1(1998年)がsRGBを推奨色空間として規定
- デジタルカメラ各社が、JPEG出力のデフォルト色空間としてsRGBを採用
この結果、BT.709/sRGBは、デジタル写真・ウェブ画像・HDテレビの共通基盤となった。現在のスマートフォン、タブレット、一般的なディスプレイは、ほぼすべてsRGB色空間を標準としている。
BT.709からBT.2020への変更 - 広色域への対応
BT.2020は、4K/8K超高解像度映像とHDR(High Dynamic Range)に対応するため、2012年に策定された。主な変更点は次の通りである。
- 色域の拡大:Rec.2020色域は、Rec.709色域の約1.7倍(面積比)の範囲をカバーする。特にシアン・グリーン領域と赤・橙領域が大幅に拡張された。
- 原色座標の変更:より彩度の高い(色度図上で外側の)原色を使用することで、自然界に存在する鮮やかな色をより正確に再現できるようになった。
- 輝度係数の再調整:原色座標の変更に伴い、R成分の輝度への寄与率が増加(約21%→26%)、G成分がわずかに減少(約72%→68%)、B成分が減少(約7%→6%)した。
ただし、BT.2020色域を完全に表示できるディスプレイは、2025年時点でも限定的である。一般的な液晶ディスプレイはRec.709の約100%、広色域ディスプレイでもRec.2020の約70〜85%程度のカバー率にとどまる。
なぜ規格が複数存在するのか
これらの規格が併存しているのは、技術の進化段階と用途の違いによる。
- BT.601:レガシーSD映像との互換性維持のために存在。新規制作では使用されない。
- BT.709:現行の標準。一般的なディスプレイ、カメラ、スマートフォンがすべて対応しており、最も広く互換性がある。
- BT.2020:将来の標準。HDR・広色域対応ディスプレイの普及とともに、徐々に移行が進んでいる段階。
デジタル写真のワークフローでは、撮影時はBT.709/sRGBで行い、必要に応じて広色域(Adobe RGB、P3、BT.2020)での編集・保存を選択するのが一般的である。
これまでY'CbCr色空間の規格について見てきたが、写真業界ではRGB色空間自体にも複数の選択肢が存在する。次に、これらの色空間規格とその用途について詳しく見ていこう。
写真における色空間の多様性
デジタル写真では、RGB色空間自体にも複数の規格が存在し、それぞれ異なる色域(カバーする色の範囲)を持つ。
- sRGB:ウェブ・一般的なディスプレイ・スマートフォンの標準色空間。BT.709とほぼ同じ原色座標を使用。色域は狭いが、互換性が最も高い。
- Adobe RGB:Adobe Systems社が1998年に策定。sRGBより約35%広い色域を持ち、特にシアン-グリーン領域の再現性が高い。オフセット印刷のCMYK色域をRGB色空間でより広くカバーすることを目的としている。
- ProPhoto RGB:Kodak社が開発。CIE 1931 xy色度図上の可視領域のほぼ全域をカバーする広色域規格。色域の約13%は人間が知覚不可能な虚色を含む。16ビット以上の色深度での使用が推奨される(8ビットでは階調不足により色帯が発生する)。
- DCI-P3:Digital Cinema Initiatives(DCI)が2005年に策定したデジタルシネマ標準。sRGBより約25%広い色域を持ち、特に赤-橙-黄色領域の再現性が高い。2015年以降、iPhone・iPad・MacBook Proなどの民生機器にも採用。
これらの色空間規格は、主に色域の広さで区別されてきた。しかし、近年のディスプレイ技術の進化により、色域だけでなく輝度範囲の拡大も重要な課題となってきている。
HDRと広色域の登場による変化
従来のSDR(Standard Dynamic Range)映像は、輝度範囲が約0.1〜100 cd/m²に制限されていた。しかし、HDR技術の登場により、0.005〜10,000 cd/m²以上の広い輝度範囲を扱えるようになった。
HDRでは、従来のガンマ2.2による符号化では輝度の階調表現が不十分となるため、新しい伝達関数が導入された。
- PQ (Perceptual Quantizer, SMPTE ST 2084)。絶対輝度値に基づく符号化。0〜10,000 cd/m²の範囲を知覚的に均等な階調で表現。Netflix、Apple TV+などで採用。
- HLG (Hybrid Log-Gamma, ITU-R BT.2100)。SDRとの後方互換性を持つ相対輝度ベースの符号化。放送業界で広く採用。
写真業界でも、Apple ProRAWやAdobe Lightroom/PhotoshopがHDR画像の編集に対応し始めており、BT.2020色空間とPQ/HLG伝達関数の組み合わせが新しい標準となりつつある。
ただし、広色域(Adobe RGB、ProPhoto RGB、P3、BT.2020)では、色差成分Cb/Crが表現する色度の範囲が拡大するため、同じサブサンプリング率(4:2:0)でも、知覚的な劣化がより顕著になる可能性がある。
具体例として、sRGB色空間でのCb/Cr値範囲は約±0.5であるのに対し、BT.2020色空間では色域が約70%拡大するため、Cb/Cr値の実効範囲も拡大する。4:2:0サブサンプリングによる空間解像度低下が、より広い色度範囲に適用されるため、色境界部でのアーティファクトが顕著化する。このため、広色域ワークフロー(デジタルシネマのDCI-P3、HDRのBT.2020)では、RAW形式(サブサンプリングなし)やProRes 4444(4:4:4:4 アルファチャンネル付き)などの非圧縮・低圧縮フォーマットが使用される。
ここまでで、色空間の多様性とその歴史的背景を理解した。では、実際にRGBからY'CbCrへの変換はどのような数学的構造を持つのだろうか。そして、情報が失われるのはどの段階なのか。次にこれらの点を明確にしていこう。
色空間変換の数理的構造
RGBからY'CbCrへの順変換
RGBからY'CbCrへの変換は、次の線形変換で表される。
\[\begin{aligned} \begin{bmatrix} Y' \\ Cb \\ Cr \end{bmatrix} = \begin{bmatrix} K_R & K_G & K_B \\ a_{21} & a_{22} & 0.5 \\ 0.5 & a_{32} & a_{33} \end{bmatrix} = \begin{bmatrix} R' \\ G' \\ B' \end{bmatrix} \end{aligned}\]
ここで、\(K_R\)、\(K_G\)、\(K_B\) は規格(BT.601、BT.709、BT.2020)ごとに定義される定数であり、\(K_R + K_G + K_B = 1\) の制約を満たす。色差成分Cb、Crの係数 \(a_{ij}\) は、\(K_R\)、\(K_G\)、\(K_B\) から導出される。
Y'CbCrからRGBへの逆変換
この変換行列は正則行列(行列式が非ゼロ)であり、逆行列が存在する。したがって、次の逆変換によって完全にRGBを復元できる。
\[\begin{aligned} \begin{bmatrix} R' \\ G' \\ B' \end{bmatrix} = \begin{bmatrix} 1 & 0 & b_{13} \\ 1 & b_{22} & b_{23} \\ 1 & b_{32} & 0 \end{bmatrix} = \begin{bmatrix} Y' \\ Cb \\ Cr \end{bmatrix}\end{aligned}\]
係数 \(b_{ij}\) は、使用する規格に依存する。
可逆性の意味
重要なのは、RGBからY'CbCrへの色空間変換自体では一切の情報損失は発生しないということである。これは可逆的な線形変換であり、数学的には完全にRGBを復元できる。
実装上は浮動小数点演算の丸め誤差が発生するが、これは無視できる程度である。8ビット整数演算で実装する場合でも、適切な丸め処理により誤差は±1階調以内に抑えられる。
それでは、どこで情報が失われるのだろうか。色空間変換が可逆であるなら、画質劣化の原因は別のところにあるはずだ。答えは次のサブサンプリングの段階にある。
サブサンプリングによる情報損失
情報が失われるのは、色空間変換ではなく、その後のサブサンプリングの段階である。ここで初めて、不可逆的なデータの削減が行われる。
重要なのは、サブサンプリングは輝度成分Y'には適用されず、色差成分Cb, Crのみに適用されるという点である。これが「4:2:0」という表記の意味するところだ。最初の「4」は輝度の完全サンプリング、後続の「2:0」は色差の間引きパターンを示している。
- 4:4:4(完全サンプリング):すべてのピクセル位置でY', Cb, Crをサンプリングするため、情報損失はゼロ。RGB色空間での完全な情報を保持する。
- 4:2:2および4:2:0:色差成分Cb, Crを間引く(量子化する)ため、空間的な色情報が不可逆的に失われる。
この情報損失は、人間視覚系の色差感度が低いという生理学的特性により、知覚的には小さく抑えられている。しかし、数学的・情報理論的には明確に情報が削減されている。
サブサンプリングの定義域
重要な原則として、クロマサブサンプリングは、Y'CbCr色空間においてのみ意味を持つ概念である。RGB色空間には、輝度と色差の分離が存在しないため、サブサンプリングの概念自体が適用できない。
ここまでで、色空間変換の可逆性と、サブサンプリングによる情報損失の本質を理解した。それでは、実際のサブサンプリングパターンがどのような数理的構造を持つのかを詳しく見ていこう。
サブサンプリングパターンの数理的定義
Y'CbCr色空間への変換が完了したので、次は実際にどのようなパターンでサブサンプリングが行われるのかを数式で定義する。
4:4:4 - 完全サンプリング
4:4:4パターンでは、輝度成分Y'と色差成分Cb, Crのすべてが、全ピクセル位置でサンプリングされる。これはRGB各チャンネルを完全に保存することと情報理論的に等価である。
\(n \times m\) ピクセルの画像に対して、各成分のサンプル数は
\[\begin{aligned} N_{Y'} = N_{Cb} = N_{Cr} = n \times m \end{aligned}\]
これが基準となる状態である。では、色差成分を間引くとデータ量はどれだけ削減できるのだろうか。まずは水平方向のみのサブサンプリングを見てみよう。
4:2:2 - 水平サブサンプリング
4:2:2パターンでは、色差成分が水平方向に2:1の比率でサブサンプリングされる。各成分のサンプル数は
\[\begin{aligned} N_{Y'} &= n \times m \ N_{Cb} &= N_{Cr} = \frac{n}{2} \times m \end{aligned}\]
データ量の削減率は、4:4:4を基準として
\[\begin{aligned} \frac{N_{4:2:2}}{N_{4:4:4}} = \frac{n \times m + 2 \times \frac{n}{2} \times m}{3 \times n \times m} = \frac{2}{3} \approx 66.7\% \end{aligned}\]
水平方向のみのサブサンプリングでも、すでに3分の1のデータ削減が実現されている。しかし、さらなる圧縮が可能である。次に、垂直方向にもサブサンプリングを適用した場合を見てみよう。
4:2:0 - 水平・垂直サブサンプリング
4:2:0パターンでは、色差成分が水平・垂直両方向に2:1の比率でサブサンプリングされる。各成分のサンプル数は
\[\begin{aligned} N_{Y'} &= n \times m \ N_{Cb} &= N_{Cr} = \frac{n}{2} \times \frac{m}{2} = \frac{nm}{4} \end{aligned}\]
データ量の削減率は
\[\begin{aligned} \frac{N_{4:2:0}}{N_{4:4:4}} = \frac{n \times m + 2 \times \frac{nm}{4}}{3 \times n \times m} = \frac{3}{6} = 50\% \end{aligned}\]
この50%という削減率が、4:2:0が広く採用される主要因である。
4:1:1 - 非対称サブサンプリング(歴史的)
4:1:1パターンは、色差成分を水平方向に4:1の比率でサブサンプリングし、垂直方向は間引かない。各成分のサンプル数は
\[\begin{aligned} N_{Y'} &= n \times m \ N_{Cb} &= N_{Cr} = \frac{n}{4} \times m \end{aligned}\]
データ量の削減率は
\[\begin{aligned} \frac{N_{4:1:1}}{N_{4:4:4}} = \frac{n \times m + 2 \times \frac{n}{4} \times m}{3 \times n \times m} = \frac{3}{6} = 50\% \end{aligned}\]
4:2:0と同じ50%の削減率を持つが、水平方向により強い間引きを行い、垂直方向は保持する。DV(Digital Video)規格など、一部のビデオフォーマットで採用されたが、現在ではほとんど使用されない。横縞パターンには強いが、縦縞パターンに弱いという非対称性が主な欠点である。
サブサンプリングパターンの数理的構造を理解したところで、次に重要な問いが浮かぶ。「なぜ色情報を50%も削減しても、視覚的な劣化が少ないのか?」この答えは、人間の知覚特性にある。
量子化と知覚
サブサンプリングによって物理的なデータ量は大幅に削減されるが、知覚的な劣化が小さいのはなぜだろうか?これには人間の知覚システムの特性が深く関わっている。
ウェーバー・フェヒナーの法則
人間の知覚は、刺激の物理的強度に対して対数的に応答する。これをウェーバー・フェヒナーの法則という。
\[\begin{aligned} S = k \ln I + C \end{aligned}\]
ここで、\(S\) は知覚される感覚量、\(I\) は物理的刺激強度、\(k\) と \(C\) は定数である。
この対数特性が、次の2つの技術に反映されている。
- ガンマ補正:線形光強度を非線形(約2.2乗)で符号化することで、知覚的に均等な量子化ステップを実現
- 対数量子化:DCT係数の量子化テーブルは、低周波成分ほど細かく、高周波成分ほど粗い
色差成分の知覚感度
人間視覚系の色差感度は、輝度感度の約1/2〜1/4である。これは、網膜の神経節細胞において、輝度チャンネル(M細胞経路)と色度チャンネル(P細胞経路)の空間解像度が異なることに起因する。
この生理学的事実が、4:2:0サブサンプリングでも視覚的劣化が小さい理由である。
知覚的な観点から、サブサンプリングが許容される理由を理解した。次に、実際にサブサンプリングされた画像がディスプレイにどのように表示されるのかを見ていこう。
表示プロセスとアップサンプリング
サブサンプリングされた画像データは、そのままではディスプレイに表示できない。ディスプレイに表示するには、RGB色空間への変換と、サブサンプリングされた色差成分の補間が必要になる。
色空間の逆変換
どのようなサブサンプリングパターンで保存されていても、ディスプレイでの表示時には必ずRGB色空間への逆変換が行われる。これは、ディスプレイデバイスの物理構造がRGB三原色の発光素子配列に基づいているためである。
補間フィルタの必要性
4:2:0や4:2:2で保存された画像を表示する際、サブサンプリングされた色差成分は元の解像度まで補間(アップサンプリング)される必要がある。
補間アルゴリズムとしては、次のような手法が用いられる
- 最近傍補間(Nearest Neighbor):計算コストが最小だが、ブロックノイズが発生しやすい
- バイリニア補間(Bilinear):線形補間により滑らかな結果を得る。2次補間は理論的には可能だが、3次(バイキュービック)と比較して計算コストの削減効果が小さく、品質面でのメリットも限定的であるため、実装されることはほとんどない
- バイキュービック補間(Bicubic):3次スプライン補間により高品質な結果を得る
- ランチョス補間(Lanczos):sinc関数を有限長に打ち切った窓関数を用いる補間手法。バイキュービックよりも高品質だが、計算コストが高い。リンギングアーティファクトが発生する可能性がある
理論的には、サンプリング定理に基づくsinc関数補間が理想的だが、計算コストと無限長のフィルタ係数から実用的でない。
理論的な基礎と表示プロセスを理解したところで、次は実際の画像フォーマットがどのようにサブサンプリングを実装しているのかを見ていこう。
各フォーマットにおける実装
ここまでで、サブサンプリングの理論的基礎と知覚的根拠を理解した。では、実際の画像フォーマットはどのようにサブサンプリングを実装しているのだろうか?各フォーマットの設計思想と実装を見ていこう。
TIFF
TIFFは主にRGB色空間で保存され、非圧縮または可逆圧縮(LZW, Deflate, PackBits等)を使用する。Y'CbCr変換を行わないため、サブサンプリングの概念自体が存在しないが、強いていうならば4:4:4相当である。
PNG
PNGは可逆圧縮フォーマットであり、RGB(A)色空間で直接保存される。Y'CbCr変換を行わないため、サブサンプリングの概念自体が存在しないが、強いていうならば4:4:4相当である。
PNGの圧縮は、次の2段階で行われる。
- フィルタリング:各スキャンラインに対して予測フィルタ(None, Sub, Up, Average, Paeth)を適用
- DEFLATE圧縮:フィルタ済みデータに対してLZ77+ハフマン符号化を適用
この方式により、完全な可逆性を保ちながら圧縮を実現する。
JPEG
JPEGは非可逆圧縮フォーマットであり、Y'CbCr 4:2:0を標準として採用している。処理の流れは次の通りである。
- RGB色空間からY'CbCr色空間への変換(可逆)
- クロマサブサンプリング(4:2:0が標準、4:2:2や4:4:4も規格上サポート)
- 8×8ブロックへの分割と離散コサイン変換(DCT)
- 量子化(視覚的に重要でない高周波成分を大きく間引く)
- エントロピー符号化(ハフマン符号化または算術符号化)
JPEG規格は4:2:2および4:4:4もサポートしているが、実際には4:2:0がデフォルトとして広く使われている。これは、ウェブ配信や一般的な写真保存において、ファイルサイズと画質のバランスが最も優れているためである。
詳細な圧縮アルゴリズムについては、付録A「JPEG圧縮アルゴリズムの詳細」を参照されたい。
WebP
WebPは、Googleが2010年に発表した画像フォーマットであり、ウェブページの読み込み高速化を主目的として設計された。単一フォーマットで非可逆圧縮と可逆圧縮の両方をサポートする点が特徴である。
非可逆WebPにおけるクロマサブサンプリング
非可逆WebPは、VP8ビデオコーデックを基礎とし、Y'CbCr 4:2:0を採用している。VP8の仕様上、4:2:0のみがサポートされており、4:2:2や4:4:4は使用できない。これは、ウェブ配信における効率性を最優先した設計である。
可逆WebP
可逆WebPは、RGB色空間で直接処理を行うため、Y'CbCr変換もクロマサブサンプリングも行わない。事実上4:4:4相当である。
WebPの位置づけ
WebPは主要ブラウザすべてでサポートされており(2025年時点)、ウェブ配信における最終出力フォーマットとして広く使用されている。JPEGと同等の視覚品質で約25〜35%のファイルサイズ削減を実現する。
詳細な圧縮技術については、付録B「WebP圧縮技術の詳細」を参照されたい。
HEIF/HEIC - 4:2:0実装とHDR対応
HEIFは、HEVC(H.265)画像コーデックを基礎とする。HEVCはMain 10プロファイルで4:2:2をサポートしており、10ビット深度での4:2:2保存が可能である。
ただし、現実の問題として次の点がある。
- Adobe Photoshopでの対応が不完全
- 4:2:2エンコード/デコードの実装が少ない
- ほとんどのカメラは4:2:0で出力
このため、技術的可能性と実用性の間にギャップが存在する。
主要な画像フォーマットの実装状況を見てきたが、ここで一つの疑問が浮かぶ。動画では標準的に使われる4:2:2が、なぜ静止画フォーマットではほとんど存在しないのだろうか。JPEG、WebP、HEIFのいずれも4:2:0を採用し、4:2:2は実質的に使われていない。この謎を解明していこう。
4:2:2が静止画で普及しない理由
各フォーマットの実装を見てきて、一つの明確なパターンが浮かび上がってきた。静止画フォーマットは「完全保存型(PNG、TIFF)」か「高圧縮型(JPEG、WebP非可逆モード)」のどちらかに二極化しており、中間的な4:2:2がほとんど存在しない。なぜだろうか?
二極化の原理
静止画フォーマットは、次の2つのカテゴリに二極化している。
完全保存型
- PNG, TIFF, BMP, WebP可逆モード, RAWフォーマット
- RGB色空間で保存(Y'CbCr変換なし)
- サブサンプリングなし(事実上4:4:4)
- 用途として、編集、アーカイブ、マスター保存
高圧縮型
- JPEG, WebP非可逆モード, HEIF
- Y'CbCr 4:2:0で保存
- 用途として、Web配信、最終出力、容量制限環境
この二極化により、中間的な4:2:2の需要が存在しない。
それでは、なぜ動画では4:2:2が標準的に使われているのだろうか。この対比を通じて、静止画における4:2:2不在の理由がより明確になる。
動画との対比
動画制作では、4:2:2が標準的に使用される。
- ProRes 422:Apple社の中間コーデック
- DNxHD/DNxHR:Avid社の中間コーデック
- XAVC-I:Sony社の収録フォーマット
動画で4:2:2が重要な理由として次が挙げられる。
- 編集耐性:カラーグレーディングやクロマキー合成で4:2:0では不十分
- フレーム数:60秒の動画は1800フレーム(30fps)以上。1フレームあたりのデータ量削減が重要
- リアルタイム性:収録・編集時のデータ転送レートとストレージ速度の制約
- 放送規格:HD-SDI(HD Serial Digital Interface)等の業務用インターフェースが4:2:2を標準とする
参考
- SMPTE (Society of Motion Picture & Television Engineers) 公式サイト - 技術標準
動画で4:2:2が必要とされる理由を理解したところで、改めて静止画のワークフローを見てみよう。なぜ静止画では異なる戦略が取られるのだろうか。
静止画ワークフローの構造
写真のワークフローは、次のような段階的構造を持つ。
撮影(RAW 12-14bit)
↓
編集(TIFF 16bit RGB)
↓
最終出力(JPEG 8bit 4:2:0)
このワークフローでは、編集段階では完全なデータを保持し、最終出力で一気に圧縮する。中間フォーマットとしての4:2:2の必要性が生じない。
一方、動画のワークフローは次のようになる。
撮影(RAW/Log 10-12bit 4:2:2)
↓
編集(ProRes 422 10bit)
↓
最終出力(H.264/H.265 8bit 4:2:0)
理想を言えばRAWデータでそのまま編集することだが、現実的には編集段階でも4:2:2を維持することで折り合いをつけ、カラーグレーディング等の編集耐性とデータ量のバランスをとる。
静止画と動画のワークフローの違いが、サブサンプリング戦略の違いを生み出していることが分かった。静止画は単一画像の完全性を重視し、動画は連続フレームの効率的な処理を重視する。この根本的な違いが、4:2:2の有無を決定している。ここまでの議論を整理し、全体像をまとめよう。
まとめ
クロマサブサンプリングは、人間視覚系の特性を利用した効率的な画像符号化技術である。その数理的基礎と実装を整理すると、次のようになる。
- 色空間の分離。サブサンプリングはY'CbCr色空間でのみ意味を持つ
- サンプリングパターン。4:4:4(完全)、4:2:2(水平1/2)、4:2:0(水平・垂直1/4)
- データ量削減。4:2:2は66.7%、4:2:0は50%
- フォーマット実装として次が挙げられる。
- 完全保存型(PNG, TIFF)はRGB、サブサンプリングなし
- 高圧縮型(JPEG, WebP非可逆)はY'CbCr 4:2:0
- 4:2:2の不在。静止画は「完全保存」か「高圧縮」かの二極化により、中間的な4:2:2の需要が存在しない
動画と静止画でサブサンプリング戦略が異なるのは、ワークフローの構造と編集要件の違いに起因する。動画では連続フレームの処理とリアルタイム性が重要であり、4:2:2が編集と容量のバランス点となる。静止画では単一画像の完全性が優先され、段階的な圧縮ワークフローが適用される。
技術的理解としては、4:2:0が「劣化」というよりも、人間視覚系に最適化された「知覚的に等価な符号化」であると認識することが重要である。
付録A: JPEG圧縮アルゴリズムの詳細
JPEGは非可逆圧縮フォーマットであり、次の5つの処理ステップで圧縮を行う。ここでは、各ステップの数理的基礎と実装の詳細を解説する。
処理ステップ1 - 色空間変換
RGB色空間からY'CbCr色空間への線形変換を行う。前述の通り、この処理自体は可逆的であり、情報損失は発生しない。
処理ステップ2 - クロマサブサンプリング
色差成分Cb, Crを空間的に間引く。これが、JPEG圧縮における最初の不可逆的データ削減である。
- 標準設定。4:2:0サブサンプリング(色差成分を水平・垂直ともに1/2に間引く)
- 高画質設定。4:4:4(サブサンプリングなし)または4:2:2(水平方向のみ1/2に間引く)
- 輝度成分Y'は間引かれない。人間視覚系の輝度感度が高いため
この処理により、色差成分のデータ量が大幅に削減される。4:2:0の場合、色差成分は元の1/4のサンプル数となる。
処理ステップ3 - 離散コサイン変換(DCT - Discrete Cosine Transform)
DCTとは何か
離散コサイン変換は、空間領域の画像データを周波数領域に変換する数学的手法である。これにより、画像の「滑らかな変化(低周波成分)」と「急激な変化(高周波成分)」を分離できる。
なぜ8×8ブロックなのか
JPEGがDCTのブロックサイズとして8×8を採用した理由は、次の3つの要因による。
- 計算コストとメモリ効率のバランス
- DCTの計算量は \(O(N^4)\)(\(N\)はブロックサイズ)で増加する
- 8×8は、1980年代の計算機でリアルタイム処理が可能な最大サイズだった
- より大きいブロック(16×16など)は計算コストが16倍になる
- 周波数分解能と空間分解能のトレードオフ
- 小さいブロック(4×4など)はブロックノイズが目立ちやすく、周波数分解能が不足
- 大きいブロック(16×16など)はブロック内で画像特性が変化しやすく、圧縮効率が低下
- 8×8は、自然画像の典型的なテクスチャサイズ(約1〜2度の視野角)に適合
- ハードウェア実装の容易性
- 8×8 = 64要素は、1980年代のメモリアーキテクチャで扱いやすいサイズ
- 高速DCTアルゴリズム(Chen-Wangアルゴリズムなど)が8×8に最適化されていた
現代の動画コーデック(H.264/AVC, H.265/HEVC)では、4×4, 8×8, 16×16, 32×32など可変ブロックサイズを使用するが、JPEG策定時(1992年)の技術制約により8×8が固定された。
JPEGにおけるDCTの具体的処理
- 画像を8×8ピクセルのブロックに分割
- 各ブロックに対して、2次元DCTを適用
- 結果として、8×8のDCT係数行列を得る
DCT係数行列における周波数成分の配置
DCT変換後の8×8係数行列は、次のような構造を持つ。
低周波 →→→→→→→→ 高周波(水平方向)
↓ (0,0) (0,1) (0,2) ... (0,7)
↓ (1,0) (1,1) (1,2) ... (1,7)
↓ (2,0) (2,1) (2,2) ... (2,7)
↓ ... ... ... ... ...
高周波 (7,0) (7,1) (7,2) ... (7,7)
(垂直方向)
なぜ左上が低周波で、右下が高周波なのか
これは、DCTの数学的定義から直接導かれる性質である。DCT係数 \(F(u, v)\) は、座標 \((u, v)\) の周波数成分の強度を表す。
- \(u\) は水平方向の周波数。\(u=0\) は直流成分(平均値)、\(u\) が大きいほど水平方向の急激な変化
- \(v\) は垂直方向の周波数。\(v=0\) は直流成分、\(v\) が大きいほど垂直方向の急激な変化
具体例として次のような対応になる。
- \(F(0, 0)\)(左上)はDC成分。ブロック全体の平均輝度。周波数ゼロ(一定値)
- \(F(0, 7)\)(右上)は水平方向に最も急激に変化する成分(垂直の縞模様)
- \(F(7, 0)\)(左下)は垂直方向に最も急激に変化する成分(水平の縞模様)
- \(F(7, 7)\)(右下)は水平・垂直両方向に最も急激に変化する成分(市松模様のような高周波テクスチャ)
この配置により、左上から右下へ向かって周波数が単調増加するという明確な構造が生まれる。
数学的定義
8×8ブロックの画素値を \(f(x, y)\) とすると、DCT係数 \(F(u, v)\) は次式で定義される。
\[\begin{aligned} F(u, v) = \frac{1}{4} C(u) C(v) \sum_{x=0}^{7} \sum_{y=0}^{7} f(x, y) \cos\left[\frac{(2x+1)u\pi}{16}\right] \cos\left[\frac{(2y+1)v\pi}{16}\right] \end{aligned}\]
ここで、\(C(u), C(v)\) は正規化係数であり、\(u=0\) または \(v=0\) のとき \(1/\sqrt{2}\)、それ以外のとき \(1\) である。
コサイン関数の周波数パラメータ \(u, v\) が大きいほど、1ブロック内での振動回数が増える。これが、\(u, v\) が大きいほど高周波成分となる理由である。
DCT自体は可逆変換であり、逆DCTによって完全に元のデータを復元できる。しかし、次の量子化処理で高周波成分を優先的に削減することで、圧縮を実現する。
処理ステップ4 - 量子化(Quantization)
量子化は、JPEG圧縮における2番目の不可逆的データ削減であり、最も大きな圧縮効果を生む処理である。
量子化テーブルとは
量子化テーブルは、DCT係数をどの程度粗く丸めるかを定義する8×8の行列である。
なぜ量子化テーブルは8×8なのか
量子化テーブルが8×8である理由は単純で、DCT係数行列が8×8だからである。各DCT係数 \(F(u, v)\) に対して、対応する位置 \((u, v)\) の量子化ステップ \(Q(u, v)\) が定義される。
なぜ整数行列なのか
量子化テーブルが整数値で構成される理由は、次の2つである。
- 整数除算による丸め処理が前提
- 量子化の計算式は \(F_Q(u, v) = \text{round}(F(u, v) / Q(u, v))\)
- 分母が整数であれば、結果も整数となり、データ表現が簡潔になる
- 浮動小数点演算を避けることで、1992年当時のハードウェア実装が高速化された
- 量子化ステップの明確性
- 整数値は、「何段階に丸めるか」を直感的に表現する
- 例として、\(Q(u, v) = 16\) なら、係数を16で割って整数に丸める → 量子化後の値域は約1/16に圧縮
現代の実装でも整数演算が標準であり、浮動小数点量子化テーブルを使用する規格は存在しない。
輝度用と色差用の量子化テーブル
JPEGでは、輝度成分Y'用と色差成分Cb, Cr用で異なる量子化テーブルを使用する。以下に示すのは輝度用であり、色差用は別に定義される。
なぜ分ける必要があるのか?理由は、人間視覚系の特性にある。
- 輝度の知覚感度が高い:細かいディテールの変化に敏感
- 色差の知覚感度が低い:色の変化には鈍感(前述のP細胞経路の空間解像度が低い)
このため、色差用の量子化テーブルは、輝度用よりも全体的に値が大きく設定される(より粗く量子化する)。
例えば、ITU-T勧告の標準的な輝度用量子化テーブル(品質50%相当)は次の通りである。
\[\begin{aligned} Q_{50} = \begin{bmatrix} 16 & 11 & 10 & 16 & 24 & 40 & 51 & 61 \\ 12 & 12 & 14 & 19 & 26 & 58 & 60 & 55 \\ 14 & 13 & 16 & 24 & 40 & 57 & 69 & 56 \\ 14 & 17 & 22 & 29 & 51 & 87 & 80 & 62 \\ 18 & 22 & 37 & 56 & 68 & 109 & 103 & 77 \\ 24 & 35 & 55 & 64 & 81 & 104 & 113 & 92 \\ 49 & 64 & 78 & 87 & 103 & 121 & 120 & 101 \\ 72 & 92 & 95 & 98 & 112 & 100 & 103 & 99 \end{bmatrix} \end{aligned}\]
重要な特徴として次の点が挙げられる。
- 左上(低周波)の値が小さい:低周波成分は細かく保存(16, 11, 10など)
- 右下(高周波)の値が大きい:高周波成分は粗く丸める(121, 120, 103など)
これは、人間視覚系が高周波成分の変化に鈍感であることを利用している。
量子化の計算
DCT係数 \(F(u, v)\) を量子化テーブル \(Q(u, v)\) で量子化する処理は、次式で定義される。
\[\begin{aligned} F_Q(u, v) = \text{round}\left(\frac{F(u, v)}{Q(u, v)}\right) \end{aligned}\]
ここで、\(\text{round}(\cdot)\) は最も近い整数への丸め処理である。
品質パラメータとの関係
多くのソフトウェアで指定する「JPEG品質」(0〜100)は、量子化テーブルのスケーリング係数に変換される。
- 品質100:量子化テーブルのすべての値を1にする(ほぼ無劣化)
- 品質50:標準の量子化テーブルを使用
- 品質1:量子化テーブルのすべての値を255にする(最大圧縮・最大劣化)
具体的なスケーリング式(IJG libjpegの実装)は次の通りである。
- 品質 \(q \geq 50\) のとき、スケーリング係数 \(s = \frac{200 - 2q}{100}\)
- 品質 \(q < 50\) のとき、スケーリング係数 \(s = \frac{5000}{q}\)
量子化後の係数は \(Q_{\text{scaled}}(u, v) = \lfloor Q_{50}(u, v) \times s / 100 \rfloor\) となる。
重要な特性
同じ品質設定でも、画像の内容によって圧縮率と視覚品質が大きく異なる。これは、画像の周波数特性(細かいディテールの多さ)によって、量子化で削減される情報量が変わるためである。
- 平坦な画像(空、グラデーション)は高周波成分が少ないため、量子化による劣化が小さく、高圧縮率を達成
- ディテールの多い画像(テクスチャ、細かい模様)は高周波成分が多いため、量子化による劣化が顕著になりやすい
処理ステップ5 - エントロピー符号化(Entropy Coding)
量子化後のDCT係数は、多くのゼロ値を含む疎な行列となる。エントロピー符号化は、この統計的偏りを利用してデータサイズをさらに削減する可逆圧縮技術である。
エントロピー符号化とは
エントロピー符号化は、出現頻度の高いシンボルに短い符号を、出現頻度の低いシンボルに長い符号を割り当てることで、平均符号長を削減する手法である。情報理論におけるシャノンのエントロピー(情報量の理論的下限)に近づけることを目的とする。
JPEGで使用される2つの方式
- ハフマン符号化(Huffman Coding)
- JPEG規格の標準方式
- 各シンボルの出現頻度に基づいて、最適な可変長符号を構築
- 出現頻度の高いゼロ値には短い符号(例として2〜3ビット)、出現頻度の低い大きな係数には長い符号(例として16ビット以上)を割り当てる
- エンコード・デコードが高速で、ハードウェア実装も容易
- 算術符号化(Arithmetic Coding)
- JPEG規格のオプション方式
- ハフマン符号化より5〜10%程度高い圧縮率を達成可能
- 計算コストが高く、特許の問題(現在は期限切れ)があったため、普及度が低い
ジグザグスキャン
エントロピー符号化の前に、8×8のDCT係数行列を1次元配列に変換する必要がある。JPEGでは、低周波成分から高周波成分へと斜め方向に走査する「ジグザグスキャン」を使用する。
0 → 1 5 → 6
↓ ↗ ↓
2 → 4 7
↓ ↗ ↓
3 ...
この順序により、非ゼロ係数が前方に集中し、後方に長いゼロランが形成される。これにより、ランレングス符号化(連続するゼロの個数を1つの符号で表現)が効果的に機能する。
圧縮効果
エントロピー符号化による圧縮率は、典型的には1.5〜3倍程度である。量子化後のデータがすでに大幅に削減されているため、エントロピー符号化の寄与は相対的に小さいが、可逆圧縮であるため視覚品質への影響はゼロである。
JPEGにおける4:2:0の位置づけ
以上の5つの処理ステップのうち、不可逆的なデータ削減は次の2箇所で発生する。
- クロマサブサンプリング(ステップ2):色差成分の空間解像度を削減
- 量子化(ステップ4):DCT係数を粗く丸めることで、主に高周波成分を削減
4:2:0サブサンプリングは、量子化と組み合わせることで、人間視覚系に最適化された高効率圧縮を実現する。
JPEGの設計思想は「視覚的劣化を最小限に抑えながら、ファイルサイズを大幅に削減する」ことである。4:2:2(データ量66.7%)よりも4:2:0(データ量50%)の方が、削減効果が大きく、かつ視覚的劣化も許容範囲内である。
JPEG規格上は4:2:2サンプリングもサポートされているが、デコーダの実装コストと普及率の問題から、実質的に使用されることはほとんどない。
WebP - Googleが設計したウェブ最適化フォーマット
WebPは、Googleが2010年に発表した画像フォーマットであり、ウェブページの読み込み高速化を主目的として設計された。HTTP Archiveの調査によれば、ウェブページのバイト数の60〜65%を画像が占めており、画像サイズの削減はページ表示速度の向上に直結する。特にモバイル環境では、帯域幅とバッテリー消費の両面で重要である。
WebPの最大の特徴は、単一フォーマットで非可逆圧縮と可逆圧縮の両方をサポートする点である。これにより、JPEG(非可逆)、PNG(可逆)、GIF(アニメーション)のすべてを置き換える可能性を持つ。
付録B: WebP圧縮技術の詳細
WebPは、単一フォーマットで非可逆圧縮と可逆圧縮の両方をサポートする。ここでは、各圧縮技術の数理的基礎と実装の詳細を解説する。
WebPの主要機能
- 非可逆圧縮:VP8ビデオコーデックを基礎とし、JPEGと同等の視覚品質で約25〜35%のファイルサイズ削減を実現
- 可逆圧縮:独自開発の予測変換とエントロピー符号化により、PNGより約26%小さいサイズを達成
- 透明度(アルファチャンネル):8ビットアルファチャンネルを、非可逆RGB・可逆RGBの両方と組み合わせ可能。透過PNGを非可逆WebPに置き換えることで、平均60〜70%のサイズ削減
- アニメーション:フルカラーアニメーション対応。GIFの代替として、より高品質・小サイズを実現
- メタデータ:EXIF、XMP、ICCプロファイルの埋め込みに対応
非可逆WebP - VP8予測符号化の実装
つまり、非可逆WebPはY'CbCr 4:2:0でのみ動作し、4:2:2や4:4:4はサポートされない。これは、ウェブ配信という用途において、ファイルサイズ削減を最優先した設計である。
VP8の圧縮アルゴリズム構造
非可逆WebPは、VP8ビデオコーデックのイントラフレーム(キーフレーム)符号化技術を静止画に適用したものである。VP8は、動画の各フレームをマクロブロックと呼ばれる小単位に分割し、ブロック単位で予測・変換・量子化を行う。
圧縮処理の流れは、次の4ステップで構成される。
- 予測符号化(Intra Prediction)
- 離散コサイン変換(DCT)と量子化
- イン・ループフィルタリング(In-loop Filtering)
- エントロピー符号化(Arithmetic Coding)
この構造は、JPEGと類似しているが、予測符号化の高度化と算術符号化の採用により、より高い圧縮効率を実現する。
ステップ1 - 予測符号化(Intra Prediction)
マクロブロックの構造
VP8では、画像を次の3種類のマクロブロックに分割する。
- 16×16輝度ブロック:輝度成分Y'の大域的構造を表現
- 4×4輝度ブロック:輝度成分Y'の詳細構造を表現
- 8×8クロマブロック:色差成分Cb, Crを表現(4:2:0サブサンプリング済み)
予測モードの種類
各マクロブロック内で、エンコーダはすでにデコード済みの隣接ブロックから現在のブロックを予測する。この予測により、元データと予測値の差分(残差)のみを保存すればよくなるため、データ量が大幅に削減される。
VP8は、次の4つの基本予測モードを持つ。
- H_PRED(水平予測):左側の列Lを各列にコピー
- V_PRED(垂直予測):上側の行Aを各行にコピー
- DC_PRED(DC予測):上側の行Aと左側の列Lの平均値でブロック全体を埋める
- TM_PRED(TrueMotion予測):行Aと列Lの勾配を伝播させる。On2 Technologies社の特許技術に由来
4×4輝度ブロックでは、さらに6つの方向性予測モード(斜め方向の予測)が追加され、合計10種類の予測モードから最適なものが選択される。
JPEGとの違い - なぜWebPの方が効率的なのか
JPEGは、8×8ブロックを独立に変換・量子化するため、ブロック間の相関を利用できない。一方、WebPの予測符号化は、隣接ブロックの情報を活用して冗長性を削減する。
例えば、青空のような平坦な領域では、隣接ブロックとほぼ同じ色が続く。WebPは、DC_PRED(平均値予測)により、ほぼゼロに近い残差のみを保存すればよい。JPEGは、各ブロックを独立に処理するため、同じ情報を繰り返し保存する。
この予測符号化の優位性が、WebPがJPEGより約25〜35%小さいファイルサイズを実現する主要因である。
ステップ2 - DCT・量子化と適応ブロック量子化
DCT変換と量子化
予測後の残差に対して、JPEGと同様の離散コサイン変換(DCT)を適用し、周波数領域に変換する。その後、量子化により高周波成分を優先的に削減する。
この処理は、JPEGと原理的に同じである。ただし、予測符号化により残差が小さくなっているため、量子化後に残る非ゼロ係数の数が少なく、より高い圧縮率を達成する。
重要な原則 - 量子化が唯一の非可逆的ステップ
Googleの公式資料では、次のように明記されている。
量子化ステップは、ビットが非可逆的に破棄される唯一のステップです(図中のQPjによる除算)。他のすべてのステップは可逆で非破壊です。
つまり、非可逆WebPの圧縮パイプライン全体において、情報が不可逆的に失われるのは量子化の段階のみである。
- 予測符号化は差分(残差)を計算するだけであり、可逆
- DCT変換は周波数領域への変換であり、逆DCTにより完全に復元可能
- 量子化は係数を粗く丸める処理であり、唯一の非可逆的処理
- イン・ループフィルタリングはデブロッキングフィルタの適用であり、参照フレームの修正で、エンコーダ・デコーダ間で共有される処理
- 算術符号化は可逆的なエントロピー符号化
この設計により、エンコーダは量子化パラメータ(QPj)を調整するだけで、視覚品質とファイルサイズのトレードオフを制御できる。
適応ブロック量子化(Adaptive Block Quantization)
WebPの重要な差別化技術が、セグメンテーション(領域分割)に基づく適応量子化である。
画像全体を、視覚的に類似した特徴を持つ領域(セグメント)に分割する。VP8では最大4つのセグメントを使用できる(ビットストリームの制限)。各セグメントごとに、次のパラメータを個別に調整する。
- 量子化ステップ:滑らかな領域では粗く、ディテールの多い領域では細かく
- フィルタリング強度:ブロックノイズが目立ちやすい領域では強く
この適応的なビット配分により、エントロピーが低い領域(空、グラデーション)には少ないビットを、エントロピーが高い領域(テクスチャ、エッジ)には多くのビットを割り当てる。
JPEGでは、画像全体に均一な量子化テーブルを適用するため、このような柔軟性はない。適応ブロック量子化により、WebPは知覚品質を維持しながら圧縮率を向上させる。
ステップ3 - イン・ループフィルタリング
ブロックノイズの抑制
ブロックベースの圧縮では、量子化により各ブロックの境界で不連続が生じ、「ブロックノイズ」として視覚化される。WebPは、エンコードループ内でこのノイズを抑制するデブロッキングフィルタを適用する。
イン・ループフィルタリングの重要性は、次のブロックの予測に影響する点にある。フィルタリング後のデータが次の予測の参照となるため、ブロックノイズの伝播を防ぎ、予測精度を向上させる。
JPEGにはイン・ループフィルタリングが存在せず、ブロックノイズは最終出力まで残る。WebPは、この処理により中程度〜低ビットレートでの視覚品質を大幅に改善する。
ステップ4 - 算術符号化(Arithmetic Coding)
エントロピー符号化の高度化
JPEGがハフマン符号化を使用するのに対し、WebPはブール算術符号化(Boolean Arithmetic Coding)を採用する。
算術符号化の原理
算術符号化は、入力データ全体を単一の浮動小数点数(0以上1未満の区間)として表現する、高度なエントロピー符号化技術である。ハフマン符号化が各シンボルに整数ビット長を割り当てるのに対し、算術符号化は分数ビット長を実現できる。
基本的な処理手順は次の通りである。
- 初期状態として、区間 \([0, 1)\) を用意する
- 各シンボルの出現確率に基づいて、現在の区間をサブ区間に分割する
- 入力シンボルに対応するサブ区間を新しい現在区間とする
- すべてのシンボルを処理するまで、2-3を繰り返す
- 最終的な区間内の任意の値を、その区間を一意に特定できる最短のビット列で表現する
具体例 - 3シンボルのエンコード
アルファベット {A, B, C} があり、それぞれの確率が P(A)=0.5, P(B)=0.3, P(C)=0.2 であるとする。シーケンス "BAC" をエンコードする過程を見てみよう。
ステップ1:初期区間 \([0, 1)\) の分割
各シンボルに確率に応じた区間を割り当てる。
- A → \([0.0, 0.5)\)
- B → \([0.5, 0.8)\)
- C → \([0.8, 1.0)\)
ステップ2:最初のシンボル 'B' の処理
シンボルBに対応する区間 \([0.5, 0.8)\) が新しい現在区間となる。
ステップ3:2番目のシンボル 'A' の処理
現在の区間 \([0.5, 0.8)\) を、再び確率に基づいて分割する。区間の長さは \(0.3\) なので、各シンボルの割り当ては次のようになる。
- A → \([0.5, 0.5 + 0.3 \times 0.5) = [0.5, 0.65)\)
- B → \([0.65, 0.65 + 0.3 \times 0.3) = [0.65, 0.74)\)
- C → \([0.74, 0.8)\)
シンボルAに対応する \([0.5, 0.65)\) が新しい現在区間となる。
ステップ4:3番目のシンボル 'C' の処理
現在の区間 \([0.5, 0.65)\) を分割する。区間の長さは \(0.15\) である。
- A → \([0.5, 0.575)\)
- B → \([0.575, 0.620)\)
- C → \([0.620, 0.650)\)
シンボルCに対応する \([0.620, 0.650)\) が最終区間となる。
ステップ5:最終区間のビット列への変換
区間 \([0.620, 0.650)\) を一意に特定できる最短のビット列を求める。
\(0.620\) を二進数で表現すると、\(0.100111\ldots\) となる。\(0.650\) は \(0.101001\ldots\) となる。両方の値が含まれる最短の接頭辞は \(0.1001\) (十進数で \(0.5625\)) である。
したがって、"BAC" は 4ビット "1001" としてエンコードされる。
ハフマン符号化との比較
同じシーケンス "BAC" をハフマン符号化した場合を考える。各シンボルには整数ビット長が割り当てられる。
- A: 1ビット("0"、出現確率50%)
- B: 2ビット("10"、出現確率30%)
- C: 2ビット("11"、出現確率20%)
"BAC" は "10" + "0" + "11" = "10011" の5ビットとなる。
算術符号化は4ビット、ハフマン符号化は5ビットであり、算術符号化の方が理論的エントロピー(約4.23ビット)により近い。
WebPのブール算術符号化
WebPが使用するブール算術符号化は、VP8動画コーデックから継承された実装である。一般的な算術符号化との主な違いは次の点である。
- 二値(バイナリ)専用:各シンボルは0か1のみ(ブール値)であり、多値シンボルは二値決定木に変換される
- 整数演算:浮動小数点演算を避け、8ビット確率テーブルと整数演算のみで実装される
- 適応的確率更新:エンコード中に確率モデルが動的に更新される
二値化の例
量子化後のDCT係数を考える。係数値は次のような情報に分解される。
- 係数がゼロか非ゼロか(1ビット決定)
- 非ゼロの場合、正か負か(1ビット決定)
- 絶対値が1か、1より大きいか(1ビット決定)
- 絶対値が2か、2より大きいか(1ビット決定)
- 以下、絶対値の各ビットを順次エンコード
各決定は、コンテキスト(周辺の係数の状態)に基づいた確率モデルを使用してエンコードされる。例えば、「左上のブロックで多くの非ゼロ係数があった場合、現在のブロックでも非ゼロ係数が出現しやすい」といった統計的依存関係を利用する。
コンテキストベースの確率モデル
WebPは、エンコードする値の種類に応じて、複数の確率テーブルを保持する。
- DCT係数の確率モデル:周波数位置(DC成分、低周波、高周波)ごとに異なるモデル
- 予測モードの確率モデル:隣接ブロックの予測モードに基づいて、現在ブロックの予測モードの確率を推定
- 動きベクトルの確率モデル(動画の場合):隣接ブロックの動きベクトルとの相関を利用
各確率は、実際にエンコードされたデータに基づいて適応的に更新される。これにより、画像の局所的な統計特性に最適化された圧縮が実現する。
デコーダとの同期
重要な点として、エンコーダとデコーダは完全に同一の確率モデル更新ルールを使用する。デコーダは、エンコーダと同じ順序でシンボルをデコードし、同じ確率更新を行うため、確率テーブル自体をビットストリームに保存する必要はない。
これにより、メタデータのオーバーヘッドを最小化しながら、コンテキスト適応的な高効率圧縮を実現している。
算術符号化による圧縮率向上
実際の圧縮率向上は、データの統計特性に依存するが、一般的にハフマン符号化と比較して5〜10%の改善が見られる。特に、次のような状況で効果が大きい。
- シンボルの出現確率が極端に偏っている場合(例:0.9と0.1)。ハフマン符号化では最低1ビット必要だが、算術符号化では0.47ビット相当を実現
- コンテキスト依存性が強い場合。周辺情報に基づいて確率を適応的に調整できる
WebPでは、この算術符号化が最終段階で適用され、予測符号化・量子化・フィルタリングで生成されたデータを最も効率的にビットストリームに変換するを採用する。算術符号化は、ハフマン符号化より理論的なエントロピー限界に近い圧縮率を達成する。
具体的な圧縮率の向上は、約5〜10%である。この差は、予測符号化や適応量子化と比較すれば小さいが、追加の視覚劣化なしで得られる利点である。
WebPがJPEGより優れている理由のまとめ
非可逆WebPの圧縮効率の優位性は、次の4要素の組み合わせによる。
- 予測符号化(最大の要因)。隣接ブロックの相関を利用し、冗長性を削減
- 適応ブロック量子化。セグメント単位でビット配分を最適化
- イン・ループフィルタリング。ブロックノイズを抑制し、中〜低ビットレートでの品質を改善
- 算術符号化。ハフマン符号化より5〜10%高い圧縮率
これらの技術により、同等の視覚品質でJPEGより25〜35%小さいファイルサイズを実現する。
可逆WebP - 独自開発の予測・変換技術
可逆WebPは、VP8とは完全に独立した圧縮技術を使用する。RGBA色空間で直接動作し、Y'CbCr変換やサブサンプリングを行わない。
可逆圧縮は、次の2段階で構成される。
- 画像変換(Transform):ピクセル値の相関を削減し、エントロピーを低減
- エントロピー符号化:LZ77-Huffman符号化により、変換後のデータを圧縮
画像変換の種類
可逆WebPは、次の5種類の変換を組み合わせて使用する。
- 予測子変換(Predictor Transform)
- 色デコリレーション変換(Color Transform)
- Subtract Green変換
- カラーインデックス変換(Palette Transform)
- カラーキャッシュコーディング
これらの変換は、すべて可逆である。逆変換により完全に元のRGBA値を復元できる。
変換1 - 予測子変換(Spatial Prediction)
空間予測は、隣接するピクセルがしばしば相関するという性質を利用する。
画像を複数の正方形領域に分割し、各領域内のピクセルに対して次の処理を行う。
- すでにデコード済みの隣接ピクセル(スキャンライン順)から現在のピクセル値を予測
- 実際の値と予測値の差分(残差)のみをエンコード
使用可能な予測モードは13種類あり、主要なものは次の通りである。
- 左ピクセルからの予測(L)
- 上ピクセルからの予測(T)
- 左上ピクセルからの予測(TL)
- 右上ピクセルからの予測(TR)
- 平均予測(L, T, TL, TRの組み合わせ)
画像の特性(水平方向のエッジ、垂直方向のエッジ、斜め方向のエッジなど)に応じて、最適な予測モードが領域ごとに選択される。
変換2 - 色デコリレーション変換
RGB色空間では、R, G, Bの3チャンネルが互いに相関することが多い(例として、明るい領域ではRGBすべてが大きく、暗い領域ではすべてが小さい)。
色デコリレーション変換は、この相関を削減するために、次の線形変換を行う。
\[\begin{aligned} G' &= G \\ R' &= R - f_1(G) \\ B' &= B - f_2(G, R) \end{aligned}\]
ここで、\(f_1, f_2\) は、ブロックごとに最適化される変換係数である。緑成分Gは視覚的に最も重要であるため、そのまま保持し、赤と青をGに基づいて変換する。
画像をブロックに分割し、各ブロックに対して green_to_red、green_to_blue、red_to_blue の3つの変換要素を定義する。
変換3 - Subtract Green変換
色デコリレーション変換の特殊ケースとして、次の単純な変換が頻繁に有効であることが実証されている。
\[\begin{aligned} R' &= R - G \\ B' &= B - G \end{aligned}\]
この変換は、計算コストが低く、多くの自然画像で効果的である。
変換4 - カラーインデックス変換(Palette)
画像内の一意なARGB値の数が少ない(256色未満)場合、次の処理により大幅な圧縮が可能となる。
- 一意なARGB値のパレット(配列)を作成
- 各ピクセル値を、パレットのインデックス(0〜255)に置き換える
これは、GIF形式と同様の原理である。アイコン、ロゴ、イラストなど、色数の限られた画像で特に効果的である。
変換5 - カラーキャッシュコーディング
可逆WebPは、LZ77辞書圧縮(後述)により、すでにエンコード済みのピクセルパターンを再利用する。しかし、完全一致するパターンが見つからない場合でも、最近使用された色が再び出現する可能性は高い。
カラーキャッシュは、最近使用された色(典型的には32色)を保持するローカルパレットである。新しいピクセルをエンコードする際、次のいずれかを選択する。
- LZ77による後方参照(完全なパターン一致)
- カラーキャッシュからの参照(色のみ一致)
- 新規のARGB値を直接エンコード
このカラーキャッシュにより、LZ77では捉えられない短距離の色相関を効率的に圧縮できる。
LZ77後方参照(Backward Reference)
LZ77は、長さと距離のタプル (length, distance) により、過去のピクセルパターンを参照する辞書圧縮技術である。
- 長さ(length)はスキャンライン順にコピーするピクセル数
- 距離(distance)は何ピクセル前からコピーを開始するか
例えば、(50, 200) は「200ピクセル前の位置から50ピクセルをコピー」を意味する。
可逆WebPは、LZ77の2次元拡張版を使用する。1次元スキャンラインだけでなく、垂直方向・斜め方向のパターン一致も検出できる。
LZ77プレフィックス符号化
長さと距離の値は、次の2部構成で保存される。
- プレフィックスコード:エントロピー符号化(ハフマン)で保存
- 余剰ビット:そのまま(エントロピー符号化なし)で保存
この方式により、小さい値(頻出)は短い符号で、大きい値(稀)は長い符号で表現される。
エントロピー符号化 - LZ77-Huffman
すべての変換を適用した後、最終的なデータはハフマン符号化により圧縮される。可逆WebPは、次の4つの独立したハフマン符号表を使用する。
- グリーン成分の符号表
- 赤成分の符号表
- 青成分の符号表
- アルファ成分の符号表
各色チャンネルの統計的性質が異なるため、独立した符号表を使用することで圧縮効率が向上する。
アルファ付き非可逆WebP - ハイブリッド圧縮
WebPの独自機能として、RGB成分は非可逆圧縮、アルファ成分は可逆圧縮というハイブリッドモードがある。
既存フォーマットの限界
透明度が必要な画像は、従来次のいずれかで保存するしかなかった。
- PNG:RGBAすべて可逆圧縮。ファイルサイズが大きい
- GIF:1ビットアルファ(完全透明or完全不透明のみ)。半透明を表現できない
つまり、「RGBは非可逆圧縮でよいが、アルファは正確に保持したい」という要求を満たすフォーマットが存在しなかった。
WebPアルファの利点
アルファ付き非可逆WebPでは、次の処理を行う。
- RGB成分:VP8非可逆圧縮(品質パラメータで調整可能)
- アルファ成分:可逆圧縮(前述の予測・変換技術を使用)
Googleの測定によれば、次のような結果が得られている。
- アルファチャンネルの可逆圧縮は、非可逆WebP(品質90)に対してわずか22%のサイズ増加
- 透過PNGをアルファ付き非可逆WebPに置き換えることで、平均60〜70%のサイズ削減
この技術は、アイコンが多用されるモバイルサイトで特に効果的である。
WebPの実装と互換性
ブラウザサポート
- Chrome:バージョン32以降(2014年1月〜)
- Firefox:バージョン65以降(2019年1月〜)
- Edge:バージョン18以降(2018年11月〜)
- Safari:バージョン16.0以降(2022年9月〜)
- Opera:バージョン19以降(2014年1月〜)

2025年時点で、WebPは主要ブラウザすべてでサポートされており、ウェブ配信での使用に問題はない。IEは、、、
画像編集ソフトウェアのサポート
- Adobe Photoshop:プラグインにより対応
- GIMP:ネイティブ対応
- ImageMagick:ネイティブ対応
- libwebp(Google公式ライブラリ)。コマンドラインツール
cwebp(エンコード)、dwebp(デコード)
写真ワークフローにおける位置づけ
WebPは、ウェブ配信における最終出力フォーマットとして設計されている。編集マスターとしての使用は想定されていない。
典型的なワークフローは次の通りである。
撮影(RAW) → 編集(TIFF) → ウェブ出力(WebP非可逆 or JPEG) → アーカイブ(PNG/TIFF)
WebPの主要な用途として次が挙げられる。
- ウェブサイトの画像配信
- モバイルアプリの画像リソース
- SNSの画像配信
長期保存や高度な編集作業には、依然としてTIFF・RAWが使用される。WebPは非可逆圧縮による画質劣化や、レイヤー情報・16bit色深度・広色域などの編集用メタデータを保持できないため。
関連したリソース



